Due to Easter and other such complications, I didn’t end up posting a development update last week. It’s been a great fortnight, though.
Let me rummage through my notes and see what we’ve got.
User-interface and Save/Load

The user interface is looking better than ever, with improved buttons and functionality. Loading and saving games is working and operates cleanly, and loading looks particularly good in action.
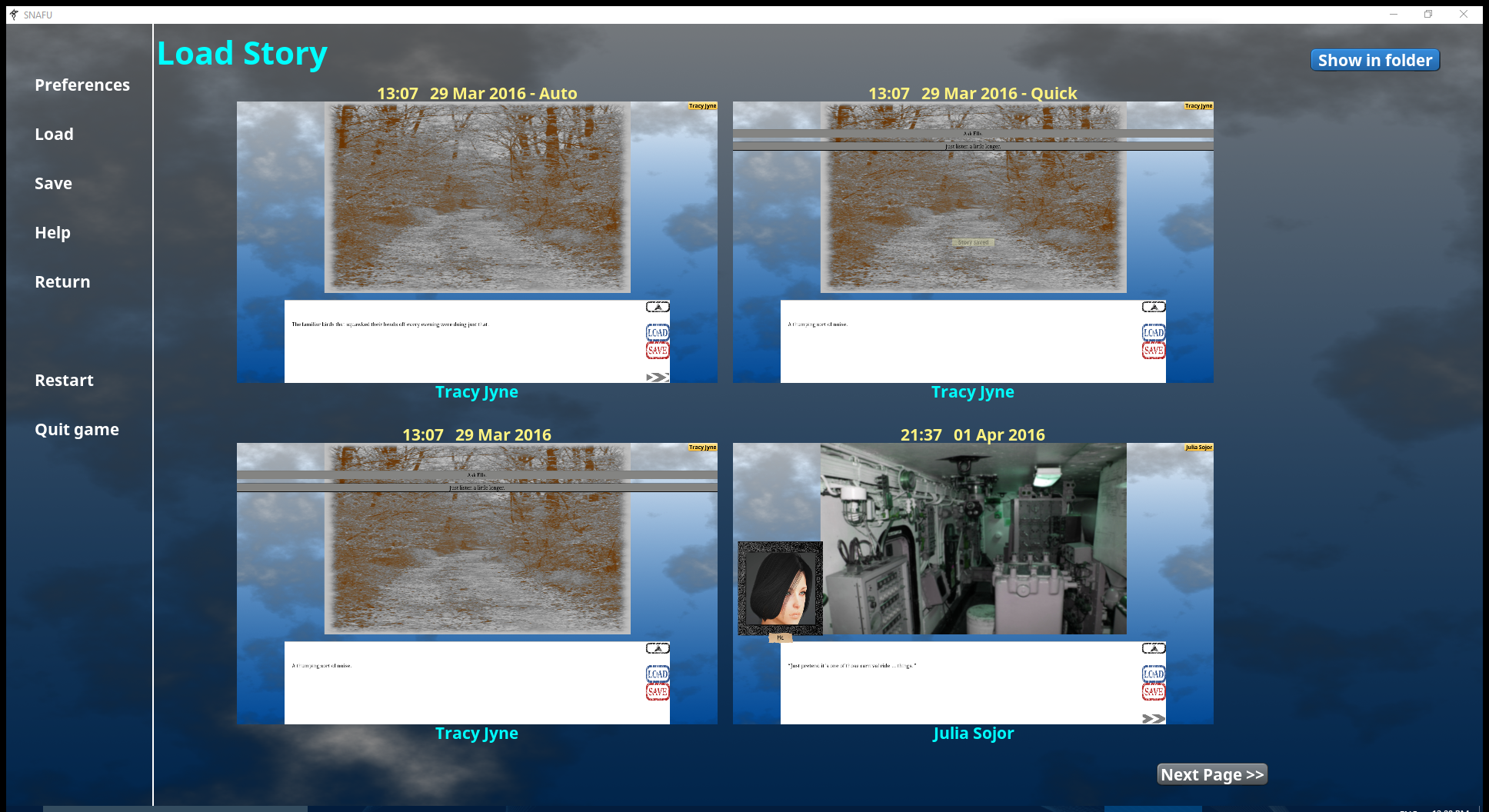
Everything on the right side of the divider scales to the current display-size, maintaining the aspect ratios so that the images don’t get distorted.
Currently there’s no widgets to delete a save. That, unfortunately, has to be done from the File Explorer right now, but that’s in the pipe to be done soon.
I discovered a bug that messed up autosave restoration,if the autosave was triggered from the options screen (ie: Selecting the options screen and quitting from there). The original code started out as a console-based application with just text and user-input, and evolved from there. Over the course of many iterations, the core story engine’s mode tracker started doing double-duty handling the UI state as well. This is what you’d call A Bad Decision.
The practical upshot of all of that is that there are combinations of game/UI states where I need to also track the previous state so that we can return to it. What I did wrong was saving the wrong system state (I should have saved the previous state, not the current state, in the case of working from the options screen). If that sounds stupidly complex it is because it is.
What I should be doing is tracking the UI states and game states separately. They’ve just never actually been separate before, so that’s going to take a little work to get right. It’s something I should plan out carefully, rather than jumping into it feet-first.
Adventures with Text
I’ve had some adventures with SDL_TTF, and, as yet, it doesn’t give me any kerning information for character-pairs, not returning an error, but always returning zero. This could be the font’s fault, as the font may not have the data encoded in a way that SDL_TTF likes.
After trying out a number of solutions, I basically added a supplementary kerning table of my own. Two characters and an integer pixel offset. It’s not ideal, but it does the job. Eyeball the text, add an entry for anything that looks weird, and that’s that.
Along the way, I hand-modified the font to add in some characters and symbols that I was missing, but that I use in the narrative. A fiddly job, and I haven’t gotten the vertical offsets of two Japanese characters quite right. I only use the two Kanji so far, but it would be nice to get those line up nicely with everything else. At least it is readable.
Variations in Narrative
So, yes I knew that there were potentially many textual variations possible in the narrative. That is kind of the point. With all eleven characters making choices throughout the story, you would expect a fair bit of variation to crop up.
What I didn’t expect was as much variation as there actually is!
I rigged up a test-mode for the game. It disables the audio, starts the game with a character that has no choices or narrative, and lets the eleven characters make their choices at random. The test-mode then loops however many times you want, counting each unique combination of character choices it encounters, and collecting every unique character transcript that is generated. All of those are then dumped to files. I also wanted to find out which transcripts occurred most and least frequently in-play. This is all good data to have!
Doing it systematically would be better, but hooray for brute-force and random numbers for getting us some pretty thorough results.
So, for the content just covered by the alpha-demo (roughly one third of the word-count, so far), the number of possible combinations of character choices is about 993! Seriously, I could have worked this out by hand, but I had honestly expected the number to be a whole lot smaller.
Combinatorial mathematics. It all adds up!
Then it was time to count how many transcript files that produced. Each of the eleven characters has their own side of the story, so we expect the number to be larger than that.
The answer was, on the order of 1,700!
The two characters with the shortest stories in the demo-content had 22 variations each, while other characters wound up with hundreds of variant narratives.
Sure, some of those variations are minor – for example, because of an event your character didn’t see, two other characters may have changed the way they address each-other. That creates variation in your narrative, even though it is minor. But choices never stop having consequences. Even small choices can snowball over time.
Counting variations in the full narrative is a bit harder. The time-per-run is longer, and more cycles are required to get proper coverage, but it is upwards of 6,000 variations.
Seriously, before I actually sat down and started testing it, I expected the whole lot to top out around 150-200 variations, max.
I lowballed that figure so very, very badly. I seriously did not (but should have!) expected the number of combinations/variations to work out anywhere near as large as they actually did!
I expect there will be some more enhancements to the test system so that I can extract a bit more data out of it all.
Fiddly bits
There’s dozens of under-the-hood changes in all of this. The lengthy and laborious set-up of all of the UI widgets has gone away. It used to take between two and 10 lines of code to set up each widget that we would use.
Now there’s a table we iterate through. It’s cleaner, faster, and if you make a bone-headed mistake, it is less trouble to find and fix.
There are now provisions for freeing image and audio resources from memory, and I can see that that will come in handy. Peak runtime memory usage at the moment is around 673MB, more or less. I’d like to make sure that doesn’t get out of hand.
There’s an experimental indexed-string class that I can switch in and out of sections of the code. The idea is to keep a master string table in-memory and just hand around/compare indexes into that table.
There’s some significant speed-improvements doing it that way, but at the current scale and style of string-usage, I’m not seeing any noticeable improvements in memory usage… yet. Will keep an eye on that.
I’ve slowed down the speed of fast-forwarding narrative, introducing a sixth-of-a-second (configurable) delay. The text used to just whizz by, which was fine for development testing, but not so good for skipping forward in actual game-play.
During play, the character name is now shown at the top right of the screen (another configurable option, you can turn it off), to remind you which character you’re actually playing. This is handy for new players, apparently, when they’re just starting out with the story.
Several character narratives have been finalised to the next narrative milestone, with only one more to go, but there’s a still a fair bit of writing to do there, I should think.
Plus, as you might expect, dozens of under-the-hood optimisations, code-cleanups, progressively-rendered widgets, and a sack-load of refactoring.
Alpha demo 4
I’ve basically got a release-candidate for the fourth alpha-demo, but I need to make sure that certain library issues aren’t a … well, an issue, before trying it out on more people. I’m not yet sure whether the VC++ redistributables will be good for the new build now that VS2015-2 is in the mix.
Hoping to have that sorted in a day or so, and distribute to a larger closed-group of testers.
I am exceptionally happy with how development has gone in the last couple of weeks. Hopefully, I’ll have another devblog up (on time, for a change!) next week!