So, a funny thing happened while I was finishing off the last of the image transitions this week…
Separation of Powers
Originally, when I did the preliminary design of Argus, I’d envisaged a core engine that was a platform-independent core, and a UI/platform-dependent layer wrapped around it.
Now, a lot of water has flowed under the bridge, as they say, and the whole application has evolved with vast chunks of it being completely rewritten… and yet, it still maintains that basic separation. The Argus engine is still underneath and cares not for your assorted platform quirks. It should just work anywhere, everywhere, with only a few small obeisances made to the lesser deities of path-separators and mmap(), and the household god of glob-matching.
While there are a few instances of weak-coupling where the engine communicates with the UI layer in an out-of-band way, the story basically was sent through a buffer of strings. The UI would pick up the next string when it was ready, break it out into the necessary bits, add in some of that out-of-band data, and presents the passage to the player.
I realised that what I basically have is a headless, portable engine, and… well, what amounts to an intricate graphical log-viewer.
From that perspective, I was able to take a couple of leaps forward. Looking at it as a log-viewer, and the transmitted data as a logged set of events, I immediately set out to expand the amount of data communicated (and fold in some of that out-of-band data).
Looking at the UI layer as a log-viewer means that I can simply communicate more complex event structures to the UI to go into the log, and then have the UI happily parse whichever log-entry it is looking at into proper user-friendly form. Now I can integrate background-music and a bunch of effects neatly with scrollback, so that when you’re scrolling back through the story, everything more or less appears as it did when it was happening “live” – if that makes any sense.
FormattableString – a small experiment in refactoring
While I’ve been making some general efforts at refactoring, not everything that needs it has fallen beneath my steely gaze.
I finally got around to taking another look at my FormattableString class. A prime-example of development laziness, I threw together some ideas, and left it alone as soon as I got a prototype version that actually worked.
FormattableString is used for every string of text that is displayed on-screen. It contains, variously, the string itself, per-character attributes, and per-character font-metrics. By font-metrics, I mean this stuff:
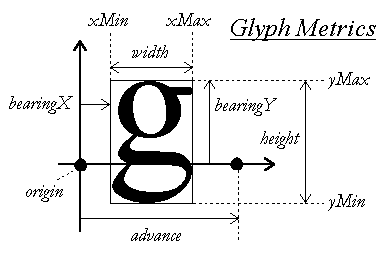
Armed with all of that information, I can calculate word-wrapping and character-placement, font-style changes and such. It’s an important data-structure, and it gets used a lot.
It was also completely rubbish. The basic design was woeful.
Internally, I had three containers. The string itself, a container of attributes, and a container of glyph-metrics (extents). The latter two had to be kept to the same length as the string at all times.
It looked like this:
class FormattableString final
{
private:
std::wstring _text;
std::vector<int> _attributes;
std::vector<CharacterExtent> _extents;
public:
enum {ATTRIB_PLAIN=0,ATTRIB_EMPH=1,ATTRIB_FOOTNOTE=2};
...
So, anytime I altered _text in any way that altered its length, I had to take time to make matching changes to _attributes and _extents. In and of itself, this doesn’t seem so bad, but it’s extra work. Worse, I’ve lost all data-locality. The actual storage of _text, _attributes, and _extents are not guaranteed to be anywhere near each-other in actual memory. They’re each contiguous in themselves, but they’re not likely to be stored together.
That didn’t occur to me at the time, though. Mostly the annoyance of keeping all three items in step size-wise (and element-wise) was what finally annoyed me into refactoring this class.
So, here’s the newer version:
class FormattableString final
{
public:
struct charpack_t
{
wchar_t text = 0;
int attributes = 0;
CharacterExtent extent;
charpack_t(wchar_t ch, int attribs, const CharacterExtent& ext)
: text(ch), attributes(attribs), extent(ext) {}
charpack_t(wchar_t ch)
: text(ch) {}
charpack_t(const charpack_t&) = default;
bool operator==(const charpack_t& o) const
{ return text == o.text&&attributes == o.attributes; }
bool operator!=(const charpack_t& o) const
{ return text != o.text || attributes != o.attributes; }
};
private:
std::vector<charpack_t> _fstring;
public:
enum { ATTRIB_PLAIN = 0, ATTRIB_EMPH = 1, ATTRIB_FOOTNOTE = 2 };
...
Now, I have a single vector, each element of which contains the three pieces of data needed per character: The character itself, its attributes, and the glyph-metrics. Each of the three are contiguous in memory, and the vector guarantees that the whole bunch of them are contiguous in memory as a group.
No more messing around with extra work to keep the lengths of containers in synch, either. For the most part, it allows me to just lean on the STL algorithms, which are mature enough to be hyper-optimised nowadays. There’s a whole lot of cases where, as a programmer, you’ll have a hard time beating the STL for sheer performance – and this constituted one of those cases.
As good refactoring should be, this didn’t change anything about how FormattableString was used by other code, so the changes just worked. And golly, how well did it work?
It was astonishing. Refactoring this one class cut processing overhead so much that the difference in display-speeds was easily noticeable. For debugging/development purposes, I have certain delays and debounce timings minimised. Holding down the Control key fast-advances the story (at an adjustable speed). With that speed cranked all the way up in my development setup, I can zip through sections of the SNAFU story very quickly.
Now it’s faster. A lot faster. About five times, I think. Up to about fifteen text passages per second or so. That’s very, very, very fast.
Absolutely, I should have revisited this class a lot sooner than I did. Actually, I only really realised that it needed improvement because I’d spent much of the last three days tidying up code and commenting it. Then I tripped over FormattableString and realised, “I can do better than this”.
I imagine there’s probably a few more like it kicking around. This code has gone through so many iterations now that there are doubtless a couple dozen areas that could do with a complete review.
I’m looking forward to it already.
Thanks for reading this week. For now, I’ve got coding and story to get back to.